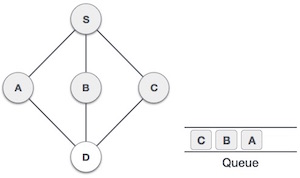
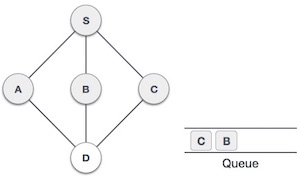
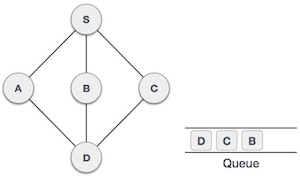
Let’s talk about Maxflow and Mincut. These are like two sides of the same coin when dealing with network flow problems. If you ever wondered how stuff moves through a network, whether its water in pipes, cars on roads, or data in a network, then youre already thinking in terms of max flow and min cut.
What is Maxflow?
Maxflow (Maximum Flow) is all about figuring out the most stuff (data, water, traffic) that can move from one point (source) to another (sink) in a network without breaking any capacity limits. Imagine a bunch of pipes carrying water, and you want to know the maximum amount of water that can flow through the system without overflowing.
What is Mincut?
Mincut (Minimum Cut) is kind of the opposite. Its about finding the weakest link in the network that, if cut, would completely stop the flow from the source to the sink. Think of it like identifying the narrowest point in a road system where a traffic jam would completely block all movement.
Maxflow and Mincut Theorem
Heres something cool: The Maxflow-Mincut Theorem says that the maximum flow in a network is equal to the total capacity of the smallest set of edges that, if removed, would stop the flow completely. This means if you
These concepts arent just theoretical; they are used in real life all the time:
- Traffic Management: Figuring out the best way to manage congestion in roads.
- Computer Networks: Making sure data packets travel efficiently.
- Airline Scheduling: Ensuring flights are assigned to routes in the best way possible.
- Water Distribution: Managing water flow in pipelines to avoid shortages.
- Project Management: Finding the critical path in workflows to improve efficiency.
Example to Understand Maxflow
Imagine a city with roads connecting different areas. If you want to get the max number of cars from the start point to the endpoint, thats maxflow. Now, let’s write code.
Maxflow using Ford-Fulkerson Algorithm
Steps to find the maxflow in a graph using the Ford-Fulkerson Algorithm:
1. Start with the initial flow as 0.
2. While there is an augmenting path from source to sink:
a. Find the path with the minimum capacity.
b. Increase the flow along the path.
3. The maximum flow is the sum of all flows along the augmenting paths.
Here’s the code to find the maxflow in a graph using the Ford-Fulkerson Algorithm:
#include <stdio.h>#include <string.h>#include <limits.h>#define V 6 // Number of vertices// Function to perform DFS and find an augmenting pathintdfs(int rGraph[V][V],int s,int t,int parent[]){int visited[V];memset(visited,0,sizeof(visited));int stack[V], top =-1;
stack[++top]= s;
visited[s]=1;while(top >=0){int u = stack[top--];for(int v =0; v < V; v++){if(!visited[v]&& rGraph[u][v]>0){
stack[++top]= v;
visited[v]=1;
parent[v]= u;if(v == t){return1;}}}}return0;}// Ford-Fulkerson algorithm to find the max-flowintfordFulkerson(int graph[V][V],int source,int sink){int rGraph[V][V];// Residual graphfor(int i =0; i < V; i++){for(int j =0; j < V; j++){
rGraph[i][j]= graph[i][j];}}int parent[V];int maxFlow =0;// Augment the flow while there is an augmenting pathwhile(dfs(rGraph, source, sink, parent)){int pathFlow = INT_MAX;for(int v = sink; v != source; v = parent[v]){int u = parent[v];
pathFlow =(pathFlow < rGraph[u][v])? pathFlow : rGraph[u][v];}
maxFlow += pathFlow;// Update the residual graphfor(int v = sink; v != source; v = parent[v]){int u = parent[v];
rGraph[u][v]-= pathFlow;
rGraph[v][u]+= pathFlow;}}return maxFlow;}intmain(){// Example graphint graph[V][V]={{0,16,13,0,0,0},{0,0,10,12,0,0},{0,4,0,0,14,0},{0,0,9,0,0,20},{0,0,0,7,0,4},{0,0,0,0,0,0}};int source =0, sink =5;printf("Maximum flow: %d\n",fordFulkerson(graph, source, sink));return0;}
Output
Following is the output of the above code:
Maximum flow: 23
Example to Understand Mincut
We already know what mincut is, let’s code to find the mincut in a graph using the Ford-Fulkerson Algorithm:
Mincut using Ford-Fulkerson Algorithm
Steps to find the mincut in a graph using the Ford-Fulkerson Algorithm:
Initialize the graph and residual graph, and set up the parent[] array to track paths. Perform BFS to find an augmenting path from source to sink in the residual graph. Update residual graph by reducing the flow along the found path and adding reverse flow. Repeat BFS until no augmenting path is found. Perform DFS to find all reachable vertices from the source in the residual graph. Print the edges that go from a reachable vertex to a non-reachable vertex, which form the minimum cut.
Now, let’s see how to find the mincut in a graph using the Ford-Fulkerson Algorithm:
#include <stdio.h>#include <string.h>#include <limits.h>#include <stdbool.h>#define V 6// Simple queue structure for BFStypedefstruct{int items[V];int front, rear;} Queue;voidinitQueue(Queue* q){
q->front =-1;
q->rear =-1;}intisEmpty(Queue* q){return q->front ==-1;}voidenqueue(Queue* q,int value){if(q->rear == V -1)return;// Queue overflowif(q->front ==-1)
q->front =0;
q->items[++(q->rear)]= value;}intdequeue(Queue* q){if(isEmpty(q))return-1;// Queue underflowint item = q->items[q->front];if(q->front == q->rear)
q->front = q->rear =-1;else
q->front++;return item;}intbfs(int rGraph[V][V],int s,int t,int parent[]){
bool visited[V];memset(visited,0,sizeof(visited));
Queue q;initQueue(&q);enqueue(&q, s);
visited[s]=1;
parent[s]=-1;while(!isEmpty(&q)){int u =dequeue(&q);for(int v =0; v < V; v++){if(!visited[v]&& rGraph[u][v]>0){enqueue(&q, v);
parent[v]= u;
visited[v]=1;}}}return(visited[t]==1);}voiddfs(int rGraph[V][V],int s, bool visited[]){
visited[s]=1;for(int i =0; i < V; i++){if(rGraph[s][i]&&!visited[i])dfs(rGraph, i, visited);}}voidminCut(int graph[V][V],int s,int t){int u, v;int rGraph[V][V];for(u =0; u < V; u++){for(v =0; v < V; v++){
rGraph[u][v]= graph[u][v];}}int parent[V];while(bfs(rGraph, s, t, parent)){int path_flow = INT_MAX;for(v = t; v != s; v = parent[v]){
u = parent[v];
path_flow =(path_flow < rGraph[u][v])? path_flow : rGraph[u][v];}for(v = t; v != s; v = parent[v]){
u = parent[v];
rGraph[u][v]-= path_flow;
rGraph[v][u]+= path_flow;}}
bool visited[V];memset(visited,0,sizeof(visited));dfs(rGraph, s, visited);for(int i =0; i < V; i++){for(int j =0; j < V; j++){if(visited[i]&&!visited[j]&& graph[i][j]){printf("%d - %d\n", i, j);}}}}intmain(){int graph[V][V]={{0,10,0,10,0,0},{0,0,5,0,0,0},{0,0,0,0,10,0},{0,0,0,0,0,20},{0,0,0,0,0,10},{0,0,0,0,0,0}};printf("Minimum Cut Edges: \n");minCut(graph,0,5);return0;}
Output
Following is the output of the above code:
Minimum Cut Edges: 0 - 3 1 - 2
Conclusion
Maxflow helps us figure out how much we can push through a system, while Mincut tells us where the weakest spots are. Both are super useful in real-life applications, from networks to transportation and beyond. Learning these concepts can help solve big optimization problems in different fields.