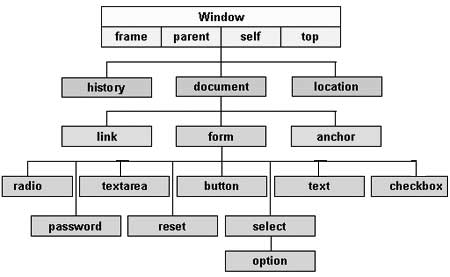
In JavaScript, with HTML DOM we can navigate the tree nodes using the relationship between the nodes. Each HTML element is represented as a node in the DOM tree. The HTML document object is represented as root node. There are different types of nodes such as root node, parent, child and sibling nodes. The relationship between these nodes help to navigate the DOM tree.
What are DOM Nodes?
When a webpage gets loaded in the browser, it creates a document object. The ‘document’ object is the root of the web page, and you can access other HTML nodes of the web page.
In the HTML DOM, everything is a node.
- The ‘document’ is a parent node of each node.
- Each HTML element is a node.
- The text inside the HTML element is a node.
- All comments inside the HTML are node is the node.
You can access all nodes of the HTML DOM.
Relationship between HTML DOM Nodes
In the HTML DOM, each node has a relationship with other nodes. Each node is present in the hierarchical structure in the DOM tree.
Here are the terms which we will use in this chapter.
- Root node − The document node is a root node.
- Parent node − Each node has a single parent node. The root node doesn’t have any parent node.
- Child node − Each node can have multiple and nested childrenders.
- Sibling node − The sibling nodes are at the same level, having the same parent node.
Let’s understand the relationship between nodes in the below example.
Example
<html><head><title> JavaScrip -DOM Navigation </title></head><body><div><h3> Hi Users!</h3><p> Hello World!</p></div></body></html>
In the above program,
- <html> is a root node, and it doesn’t have a parent node.
- The <html> node contains two child elements: <body> and <head>.
- The <head> element contains the single child element: <title>.
- The <title> node contains the single <text> node.
- The <body> element contains the single child node: <div>.
- The <div> node contains two child nodes: <h2> and <p>.
- <h2> and <p> are siblings.
- The parent of the <h2> and <p> is <div> node.
- The parent of the <div> node is <body> node.
Navigating Between Nodes Using JavaScript
Navigating between nodes means finding the parent, child, sibling, etc. element of a particular element in the DOM tree.
You can use the below methods and properties to navigate between nodes in the DOM tree.
| Property | Description |
|---|---|
| firstChild | To get the first child of the particular node. It can also return the text, comment, etc. |
| firstElementChild | To get the first child element. For example, <p>, <div>, <img>, etc. |
| lastChild | To get the last child of the particular node. It can also return the text, comment, etc. |
| lastElementChild | To get the last child element. |
| childNodes | To get the node list of all children of the particular element. |
| children | To get the HTML collection of all children of the particular element. |
| parentNode | To get the parent node of the HTML element. |
| parentElement | To get the parent element node of the HTML element. |
| nextSibling | To get the next node from the same level having the same parent node. |
| nextElementSibling | To get the next element node from the same level having the same parent node. |
| previousSibling | To get the previous node from the same level having the same parent node. |
| previousElementSibling | To get the previous element node from the same level having the same parent node. |
Below, we will use each method to navigate through the DOM elements.
Accessing the First Child Element
You can access the particular child element using the firstChild or firstElementChild property.
Syntax
Follow the syntax below to use the ‘firstChild’ and ‘firstElementChild’ properties to access the first child element.
element.firstChild; element.firstChildElement;
Example
In the below code, <div> element contains the text followed by three <p> elements.
When we use the ‘firstChild’ property, it returns the text node containing the ‘Numbers’ text, and when we use the ‘firstChildElement’ property, it returns the first
element.
<!DOCTYPE html><html><body><div id ="num">Numbers
<p> One </p><p> Two </p><p> Three </p></div><div id ="demo"></div><script>const output = document.getElementById('demo');const numbers = document.getElementById('num');// Using the firstChild property
output.innerHTML +="numbers.firstChild: "+
numbers.firstChild.textContent.trim()+"<br>";// Using the firstElementChild property
output.innerHTML +="numbers.firstElementChild: "+ numbers.firstElementChild.textContent +"<br>";</script></body></html>
Accessing the Last Child Element
You can use the lastChild or lastChildElement properties to access the last child of the particular HTML node.
Syntax
Follow the syntax below to use the ‘lastChild’ and ‘laststElementChild’ properties to access the las=st child element.
element.lastChild; element.lastChildElement;
Example
In the below code, we have defined the <div> element containing 3 <p> elements containing the name of the programming languages.
In the output, you can see that the lastElementChild property returns the last <p> element, and the lastChild property returns the text node of the div element.
<!DOCTYPE html><html><body><div id ="lang"><p> Java </p><p> JavaScript </p><p>HTML</p>
Programming Languages
</div><div id ="demo"></div><script>const output = document.getElementById('demo');const langs = document.getElementById('lang');// Using the lastChild property
output.innerHTML +="langs.lastChild: "+ langs.lastChild.textContent.trim()+"<br>";// Using the lastElementChild property
output.innerHTML +="langs.lastElementChild: "+ langs.lastElementChild.textContent +"<br>";</script></body></html>
Accessing all children of HTML Element
You can use the childNodes property to access the node list of all children elements or the children property to access the HTML collection of all children.
Syntax
Follow the syntax below to access all children elements of the DOM element.
element.children; element.childNodes;
Example
In the below code, we use the childNodes property to access all child nodes of the <div> element.
In the output, you can see that it also returns the text nodes with undefined text as it contains the text nodes after and before each HTML element node.
<!DOCTYPE html><html><body><div id ="lang"><p> Java </p><p> JavaScript </p><p>HTML</p>
programming Languages
</div><div id ="output"></div><script>let output = document.getElementById('output');let langs = document.getElementById('lang');
output.innerHTML +="All children of the div element are - "+"<br>";let allChild = langs.childNodes;for(let i =0; i < allChild.length; i++){
output.innerHTML += allChild[i].nodeName +" "+ allChild[i].innerHTML +"<br>";}</script></body></html>
Accessing the Parent Node of HTML Element
You can use the parentNode property to access the parent node of the particular HTML node.
Syntax
Follow the syntax below to use the parentNode property.
element.parentNode;
Example
In the below code, we access the <li> element having d equal to ‘blue’ in JavaScript. After that, we use the parentNode property to access the parent node.
It returns the ‘UL’ node, which we can observe in the output.
<!DOCTYPE html><html><body><ul id ="color"><li id ="blue"> Blue </li><li> Pink </li><li> Red </li></ul><div id ="output">The child node of the color list is:</div><script>const blue = document.getElementById('blue');
document.getElementById('output').innerHTML += blue.parentNode.nodeName;</script></body></html>
Accessing the Next Sibling Node
The nextSibling property is used to access the next sibling.
Syntax
Follow the syntax below to use the nextSibling property.
element.nextSibling
Example
In the below code, we have access to the <li> element with an id equal to ‘apple’, and access to the next sibling node using the nextSibling property. It returns the <li> node having the id equal to ‘banana’.
<!DOCTYPE html><html><body><ul id ="fruit"><li id ="apple"> Apple </li><li id ="banana"> Banana </li><li id ="watermealon"> Watermealon </li></ul><div id ="output">The next sibling node of the apple node is:</div><script>const apple = document.getElementById('apple');
document.getElementById('output').innerHTML += apple.nextElementSibling.textContent;</script></body></html>
Accessing the Previous Sibling Node
The previousSibling property is used to access the previous sibling node from the DOM tree.
Syntax
Follow the syntax below to use the previousSibling property.
element.previousSibling;
Example
In the below code, we access the previous sibling of the <li> element with an id equal to ‘banana. It returns the <li> element having id equal to ‘apple’.
<!DOCTYPE html><html><body><ul id ="fruit"><li id ="apple"> Apple </li><li id ="banana"> Banana </li><li id ="watermealon"> Watermealon </li></ul><div id ="output">The previous sibling node of the banana node is:</div><script>const banana = document.getElementById('banana');
document.getElementById('output').innerHTML += banana.previousElementSibling.textContent;</script></body></html>
DOM Root Nodes
The HTML DOM contains two root nodes.
- document.body − It returns the <body> element of the document.
- document.documentElement − It returns the entire HTML document.
Example: Using the document.body
<!DOCTYPE html><html><body><div> This is demo!</div><div id="output"></div><script>const output = document.getElementById('output');
output.innerHTML +="The body of the document is: "+ document.body.innerHTML;</script></body></html>
Example: Using the document.documentElement
<!DOCTYPE html><html><body><h1> Hi, Users!</h1><div id="output"></div><script>const output = document.getElementById('output');
output.innerHTML +="The full document is "+ document.documentElement.innerHTML;</script></body></html>
DOM nodeName Property
The nodeName property of the HTML DOM element is used to get the name of the node, and it has specifications given below.
- It is read−only. You can’t modify it.
- The value of the nodeName property is equal to the tag name in the upper case.
- The node name of the text node is #text.
- The node name of the document node is #document.
Syntax
Follow the syntax below to use the nodeName property to get the name of the node.
element.nodeName;
Example
In the below code, we access the <div> element and use the nodeName property. It returns the tag name in the uppercase.
<!DOCTYPE html><html><body><div id ="output"></div><script>const output = document.getElementById('output');
output.innerHTML ="The node name of the div node is: "+ output.nodeName;</script></body></html>
DOM nodeValue Property
The nodeValue is used to get the value of the, and it has specifications given below.
- It is also a read-only property.
- The node value for the text node is the text itself.
- The node value for the element nodes is null.
Syntax
Follow the syntax below to use the nodeValue property to get the value of the node.
element.nodeValue;
Example
The <div> element contains some text, and the <p> element in the below code.
The first child element of the <div> element is the text node, and the second child node of the <div> element is the <p> element.
In the output, you can see that when you use the nodeValue property with the text node, it returns the text. Otherwise, it returns null when you use it with the HTML element node.
<!DOCTYPE html><html><body><div id ="num">
Numbers
<p> One </p></div><div id ="output"></div><script>const output = document.getElementById('output');const num = document.getElementById('num');let child = num.childNodes;
output.innerHTML +="The value of the first child is: "+ child[0].nodeValue +"<br>";
output.innerHTML +="The value of the second child is: "+ child[1].nodeValue +"<br>";</script></body></html>
Types of Node in DOM
Here, we have given different node types in the HTML DOM.
| Node | Type | Description |
|---|---|---|
| Element Nodes | 1 | The element nodes can have child nodes, attributes, and text content. For example, <div>, <a>, etc., are element nodes. |
| Text Nodes | 3 | The text nodes can have text content inside the node. For example, text inside the <p>, <div>, etc. elements. |
| Comment Nodes | 8 | The comment nodes contain the comments. |
| Document Nodes | 9 | It represents the entire document. |
| Document Type Node | 10 | It represents the type of the document. For example, <!Doctype html> |
DOM nodeType Property
The nodeType property returns the type of the node as shown in the above table.
Syntax
Follow the syntax below to use the nodeType property to get the type of the node.
element.nodeType;
Example
In the below code, we use the nodeType property to get the type of the node.
<!DOCTYPE html><html><body><div id ="output"></div><script>const output = document.getElementById('output');
output.innerHTML +="The type of the div node is: "+ output.nodeType;</script></body></html>